引入Kafka(https://blog.csdn.net/zpcandzhj/article/details/108770504)连接器pom依赖,连接器的版
”大数据 flink 计算框架“ 的搜索结果

Apache Flink 是一个流批统一的计算框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。 Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 OLTP 实时计算(流式计算) OLAP ...



Flink能够提供毫秒级别的延迟,同时保证了数据处理的低延迟、高吞吐和结果的正确性,还提供了丰富的时间类型和窗口计算、Exactly-once 语义支持,另外还可以进行状态管理,并提供了CEP(复杂事件处理)的支持。Flink...

Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。这个学习文档通俗易懂flink知识点几乎全部覆盖,...
1.什么是实时计算?流式计算举例自来水厂处理水的过程(图)特点源源不断任务类型采集数据-->Spout任务处理数据-->bolt任务2.跟离线计算的区别(1)离线计算采集数据强调是...常见的实时计算框架(3)JStorm(4)Flink。...
大数据流式处理框架Flink介绍
标签: 大数据
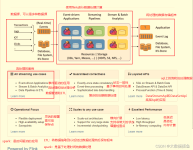
随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。 第一代:Hadoop 承载的 MapReduce 第二代:支持 DAG(有向无环图)框架的...
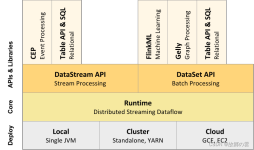
Flink是一个对有界和无界数据流进行有状态计算的分布式处理引擎和框架,既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型,其代码主要由 Java 实现,部分代码由 Scala...
随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。第一代:Hadoop承载的MapReduce第二代:支持DAG(有向无环图)框架的计算...


随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。

分布式计算框架是一种先进的软件工具,它可以将计算任务划分为多个子任务,并在多个节点上并行执行。这种框架的设计目标是为了提高计算效率,同时降低计算的复杂性。它通过资源管理器、调度器和通信库等组件的协同...
看到这篇文章,感觉写的很好,简单易懂,而且也挺全面。所以转到自己的空间里,方便以后阅读。 版权声明:本文为博主原创文章,遵循 ...
随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。 第一代:Hadoop 承载的 MapReduce 第二代:支持 DAG(有向无环图)框架的...
Flink简介 一、是什么? 1.1 起源 Flink的前身是Stratosphere项目,Stratosphere是在2010~2014年由3所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014年4月Stratosphere的代码被复制并捐赠给了Apache...
尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】



Apache Spark:Apache Spark是一个快速、通用的大数据处理框架,它支持在内存中进行高性能的数据处理。...Apache Flink:Apache Flink是一个流式计算框架,它支持在流数据和批数据上进行高性能的数据处理。
推荐文章
- python判断sqlite数据库是否存在_sqlite3 判断数据库是否存在-程序员宅基地
- android多级树形列表-程序员宅基地
- 《成为一名机器学习工程师》_成为机器学习的拉斐尔·纳达尔-程序员宅基地
- Debian11-jenkins+python+allure自动化搭建_debian11 源 tencent-程序员宅基地
- JavaScript设计模式系统讲解与应用-笔记_javascript 设计模式系统讲解与应用 课程-程序员宅基地
- sepl 3.0,全方位全能型计算机语言_sepl无人编程-程序员宅基地
- java comtext_Java中的上下文对象设计模式(Context Object Design Pattern)-程序员宅基地
- lldp中与snmp相关内容agentx-程序员宅基地
- 关闭Mysql的root用户远程访问授权报错Duplicate entry localhost-root for key PRIMARY_error 1062 (23000): duplicate entry 'localhost-roo-程序员宅基地
- LeetCode 818. Race Car-程序员宅基地